Intimidation Factor
At first, creating a model that can not only predict outcomes but can do it well is intimidating to a novice data scientist. Essentially, you are bringing an abstract concept to life that will impact the world whether that just be in a project you will present to an instructor for a Data Science course through Flatiron, or at the expense of a corporate budget.
Don’t Panic
Once you are acclimated to the development process, it is straight forward with model selection, model validation and hyperparameter tuning for a dataset.
Needed Structure
Before jumping into cleaning data and plotting anything, I gave myself structure and organization, so I could make sure I did not just get lost in the data and come out of it without meeting my project objectives. I use the Data Science Lifecycle below as my map for my data journey:
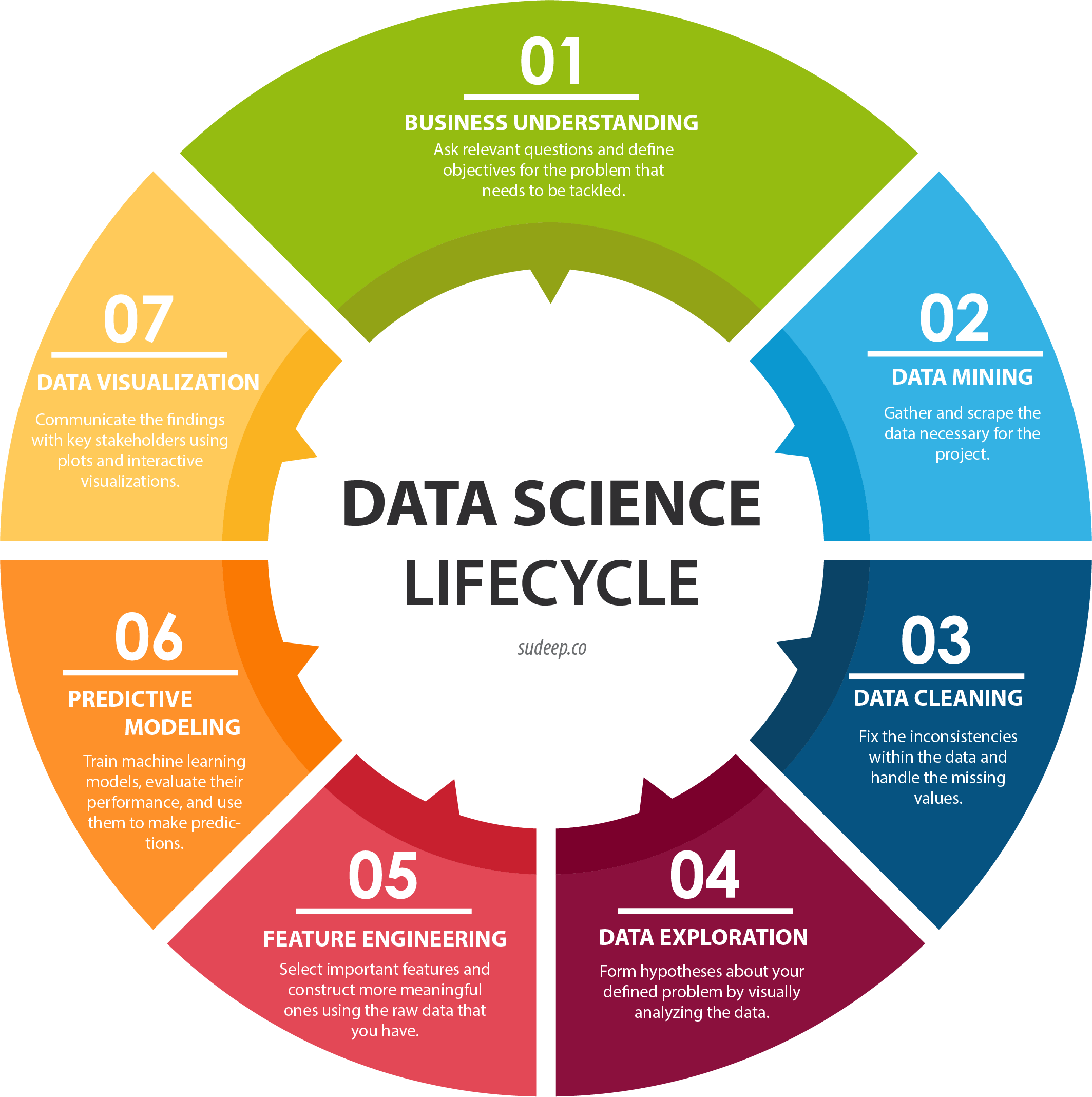 Image provided by Sudeep Agarwal
Image provided by Sudeep Agarwal
With that process, I can have a step-by-step recipe for success for all my projects–all I have to do is just follow it!
Fast Forward to Feature Engineering, Predictive Modeling and Data Visualization
After all the previous steps have been done, we will find ourselves in the intimidating stuff: bringing the best model to life.
The best model for our data is the one that selects important features and constructs more meaningful ones using our data. To achieve this, we should avoid multicollinearity of features, separate the categorical features from the continuous features, transform our data (scale, standardize, one-hot encode, etc.), and check assumptions for data (such as Linearity Assumption).
Once we have accomplished this, we can create different variables sets (inclusion of some variables while excluding others) and derive models from each. Note: do not forget to split your data up into a testing and training set! We can then easily validate how accurate and precise our models are by looking at correlations (R^2) and error evaluations such as Mean Square Error, Mean Absolute Error, etc. If we yield high correlation and low error, then we have a great model! If we do not, then still do not panic. Fine tuning what percentage of data should be test and train data could be the cause of the low correlations, high error, or both! Generally, 80% for training, and 20% for testing is a good selection.
If after doing this correlations and errors have not met a certain threshold, we can still use feature ranking functions such as recursive feature elimination to select the most important features for better model representation; this can be done on all models that failed to achieve desired correlations, high error, or both! If there are still bad results, then perhaps switching up the model type (e.g. multiple linear regression to multiple polynomial regression) and then repeating the above steps will yield better results.
DONE!
And there you have it! With your model now alive and (predicting) well, stakeholders can reap the fruit of all our work and see why data science is so powerful.
Check out my Analysis on House Prices where I go through the above process: House Sale Prices